Nota: Le présent document a été réalisé dans le cadre d'un projet de recherche sur le domaine du Data Mining. Il est certes loin d'être exhaustif mais peut constituer un bon outil de documentation pour quelques uns.
<< On ne finit jamais de découvrir. >>
Mots clés
Clustering, Classification, Data mining, Self-Organised-Map, BeSOM, E-M
Notations
X = {X1, ……,Xn} l’ensemble des données (ou individus) ;
Y = {Y1, ……,Yp} l’ensemble des variables ;
C = {C1, ……,Ck} l’ensemble des classes et G = {G1, ……, Gk} leurs centroïdes ;
P = {P1, ……, Pp} les poids des variables
Liste des Sigles et Abréviations
ACM Analyse des Correspondances Multiples
ACP Analyse en Composantes principales
BATM Bernoulli Aspect Topological Model
CAH Classification Ascendante Hiérarchique
CDH Classification Descendante Hiérarchique
GTM Generative Topographic Map
SOM Self-Organised-Map
STVQ Soft TopographicVectorQuantization
I. INTRODUCTION
Notre travail de recherche s'articule autour de l'exploration et l'extraction de connaissances à partir de données catégorielles. Nous avons cherché à développer un modèle de représentation qui résume d'une manière globale l'ensemble des données, en identifiant des proximités ou des différences entre des ensembles de données, non étiquetées à priori. Cette recherche comporte deux aspects : un aspect fondamental qui consiste à développer une technique pour la classification et la visualisation de données catégorielles, et un aspect applicatif qui consiste à valider notre approche sur différents types de données.
L’objectif du travail effectué est d’implémenter un algorithme de clustering sur des données catégorielles et de réaliser des tests. Il relève du domaine du data mining qui peut être défini comme étant l’extraction ou la recherche de connaissances à partir de volumes importants de données. Le data mining se base sur un ensemble de méthodes automatiques ou semi-automatiques pour constituer un outil d’aide à la décision.
Pour réaliser des travaux de data mining, un ensemble de techniques se trouvant à la croisée de la statistique, de l’analyse des données, de l’intelligence artificielle et des bases de données nous est proposé mais dépendant fortement de la nature des données dont on dispose et du type d’étude à entreprendre. Il existe deux grandes familles de techniques de data mining :
- Les techniques descriptives : visent à mettre en évidence des informations présentes mais cachées par le volume des données.
- Les techniques prédictives : visent à extrapoler de nouvelles informations à partir des informations présentes.
Notre travail vise plutôt à traiter des données binaires à partir de techniques descriptives. Pour ce faire, on utilisera un modèle de carte topologique basé sur le modèle de mélange. Ces cartes utilisent toutes un algorithme d’auto-organisation SOM (Self-Organised-Map). Cependant, pour mieux appréhender le thème, une brève présentation des méthodes les plus générales de la classification non-supervisée sera effectuée.
Les techniques du data mining servent principalement dans deux secteurs d’activité : la recherche et les entreprises (les banques, les télécommunications, les E-commerces, etc.)
II. ÉTAT DE L’ART
Ce travail représente une approche de classification appliquée aux données binaires. Dans notre contexte où il est question d’étudier de grandes quantités de données et on souhaite projeter les données dans un espace de faible dimension en conservant la notion de voisinage, il serait intéressant d’utiliser des méthodes auto-organisatrices comme par exemple les cartes SOM. Les cartes topologiques utilisent un algorithme d’auto-organisation qui permet de classifier et de projeter les groupes obtenus de façon non linéaire sur une carte tout en respectant la topologie initiale. Des modèles de cartes topologiques pour des données binaires ont été proposés suite à différents travaux de recherche tels que [1] et [2].
Cependant, différentes approches reposant sur le formalisme probabiliste ont été proposées. On peut citer comme référence le GTM même si au départ son champ d’application reste limité à des données continues. Nous pouvons citer [3] qui additionne la log-vraisemblance des données et un terme de pénalité qui applique l’auto-organisation. Il y a aussi le STVQ qui mesure une divergence entre les données élémentaires et les référents. Dans le document [4] les auteurs présentent le modèle BATM qui permet d’accélérer la convergence de l’estimation par une initialisation originale des probabilités en jeu.
Toutes ces études ont permis de donner des méthodes plus ou moins satisfaisantes selon les cas étudiés. Elles sont toutes applicables sur des données binaires et pour certaines uniquement sur ce type de données ; ce qui cause une certaine limite vue que la plupart des données recueillies intègrent à la fois des informations de type quantitative et catégorielle.
III. CLASSIFICATION
La classification peut être définie comme étant le regroupement en groupes similaires d’un ensemble de données. Il s’agit en d’autres termes de regrouper les données ayant le plus de similarité de tel sorte que les individus similaires appartiennent à une même classe et sont différents des individus d’autres classes.
Il existe deux grandes familles de méthodes de classification :
- Les méthodes supervisées ;
- Les méthodes non supervisées.
1. Classification supervisée
La classification supervisée porte sur une série de méthodes prédictives de classification des données. On parle de prédiction lorsqu’on veut estimer la classe à laquelle appartient une donnée à partir d’un ensemble de données déjà classées. On dispose pour ce faire d’une base de données à priori classée appelée base d’apprentissage qui nous servira de référent et d’un ensemble de données qu’on appellera base de test (qui contient les données à prédire). La problématique sera donc de prédire, pour chaque donnée de la base de test, la classe à laquelle elle appartiendra dans la base d’apprentissage.
Elle peut être illustrée comme suit :

Il existe plusieurs méthodes proposées, permettant d’effectuer la classification supervisée. On peut ainsi citer quelques unes :
- Les réseaux de neurones : Ils sont constitués d’un ensemble de «neurones formels». Ce modèle est tiré des neurones biologiques.

Fig1: Réseaux de neurones
A chaque donnée en entrée, on associe un poids . La sortie y sera la valeur à estimer et dépendra fortement de la fonction d’activation f du neurone (souvent une sigmoïde) ;
- Les arbres de décision : Dans ce cas ci, on cherche à homogénéiser les différentes classes obtenues. Notre ensemble de données est séparé de façon récursive suivant des variables déterminées (par exemple on décide de choisir comme variable de séparation la variable la plus fréquente ...).

Arbre de décision [Quinlan 1993]
- Le KNN (K-Nearest-Neighbour) : Cette méthode suppose qu’une donnée est de la même classe que celles qui lui sont proches. Autrement dit, la probabilité que les K données les plus proches (du point de vue de leur distance) soient dans une même classe est maximale. Si les K données sont dans des classes différentes, notre donnée sera attribuée à la classe la plus représentée.
1. Classification non supervisée
La classification non-supervisée comporte sur un ensemble de méthodes destinées à répartir des données dans une structure plus ou moins organisée, de regrouper les données en sous-groupes de sorte à ce que les données les plus similaires soient associées au sein d’un même groupe homogène et les données considérées comme différentes soient associées dans des groupes différents. Lors de la classification non supervisée on cherche à satisfaire deux objectifs simultanément: une grande homogénéité de chaque classe et une bonne séparation des classes.
L’objectif de la classification non-supervisée est de permettre l’extraction de connaissance à partir de ces données.
La méthode de classification non supervisée se distingue de celle supervisée par le fait qu'il n'y a pas de sortie à priori. En effet, dans une classification non supervisée il y a en entrée un ensemble de données collectées ensuite le programme les traite comme des variables aléatoires et construit un modèle de « densités jointes » pour cet ensemble de données.
Il existe plusieurs types de classification non-supervisée, on cite : Clustering hiérarchique, Clustering K-means, Clustering statistique, Clustering stochastique, etc.
Difficultés de la classification non supervisée
La classification non supervisée rencontre différentes difficultés dont les plus essentielles selon notre avis sont les suivantes :
a) Dans une zone de forte densité il est naturel de reconnaître des observations regroupées comme appartenant à une même classe, en revanche il n’est pas de même dans une zone de faible densité. La définition de frontières entre les classes peut être hasardeuse.
b) Dans le cadre de la classification non supervisée le nombre de classes est inconnu à priori. Ainsi, il est difficile de définir le nombre optimal de classes.
c) Le critère de validation des résultats constitue également une difficulté pour la classification non supervisée.
d) Pour certains algorithmes la forte dépendance de la phase d’initialisation constitue un véritable désavantage.
3. Étude de quelques algorithmes de classification non supervisée
Il existe plusieurs algorithmes de classification non supervisée donnant tous des résultats plus ou moins satisfaisants selon le type de traitement souhaité. Dans cette section nous présentons quelques uns de ces algorithmes mais qui sont les plus couramment utilisés.
a. L’approche K-means
Aussi connu sous l’appellation k-moyennes, il est l’un des outils de classification les plus utilisés dans les applications scientifiques et industrielles. Le principe étant de découper un ensemble d’observations en k classes distinctes. Son étude introduit les notions d’inertie et de barycentre. Pour rappel, le barycentre d’un nuage de points est un point pour lequel l’inertie totale est minimale ; l’inertie d’un système étant la propriété de ce dernier à rester immobile (ou en équilibre).
Plusieurs méthodes de calcul de l’inertie sont utilisées et se basent toutes sur la notion de métrique (ou distance). La métrique la plus utilisée (et sur laquelle on se basera ici) est le carré de la distance euclidienne.
Si le nombre de classes augmente (plus d’une), on est amené à calculer :
- L’inertie intraclasse : Représente l’inertie calculée pour les individus appartenant à une même classe. Elle est donnée par :
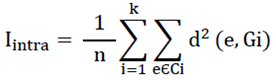
- L’inertie interclasse : Représente l’inertie calculée entre les différentes classes. Elle est donnée par la formule suivante :

- L’inertie totale : Représente l’inertie du système. Elle est donnée par la somme des inerties interclasse et intraclasse. Elle peut aussi être calculée par la formule suivante :

K-means comporte deux étapes fondamentales : une étape d’initialisation et une étape d’affectation.

Il existe plusieurs versions de k-means parmi lesquelles :
- Le k-means incrémental : Où les observations sont ajoutées les unes après les autres et le logiciel recalcule les barycentres après chaque ajout.
- Les nuées dynamiques : Où on n’initialise pas le traitement avec des observations mais avec des ensembles d’observations représentatives.
Malgré sa grande popularité, sa simplicité, sa rapidité, etc. la méthode du k-means présente néanmoins un certain nombre de désavantages. Par exemple:
1.
1. Le plus probant est la forte dépendance du nombre k de classes car l’utilisateur devra à priori renseigner le nombre de classes désiré ; ce qui fait que k-means soit le plus souvent précédé d’une ACP ou d’une ACM selon le type de données.
2. 2. Une autre faiblesse de k-means est liée aux formes des classes car pour des classes étalées, cette méthode renvoie des résultats erronés.
b. La classification hiérarchique
C’est en effet la technique de classification la plus ancienne et repose sur une métrique de dissimilarité ; c’est-à-dire définir une grandeur qui permet de différencier le différentes données recueillies. Elle se présente sous la forme d’un arbre binaire (appelé dendogramme), permettant de visualiser les classes sous une forme hiérarchisée. L’intérêt d’une telle classification réside dans la partition de l’ensemble des données en classes compactes, bien séparées et donc facilement interprétables. On en distingue deux types :
- Classification Ascendante Hiérarchique (CAH)
- Classification Descendante (ou Agglomérative) Hiérarchique (CDH).
. La classification hiérarchique ascendante
Le principe du CAH est de réaliser une agrégation deux à deux des individus (ou ensemble d’individus) les plus proches selon des critères d’agrégation à définir. Ces critères se basent sur deux aspects : les individus d’une même classe sont les plus semblables possibles ; les classes sont les plus disjointes possibles. La définition d’un tel critère est primordiale dans la mesure où on sera appelé à répondre à la question qui suit :
Comment calculer la métrique de dissimilarité entre deux classes ?
Trois critères sont généralement utilisés pour réaliser cette agrégation. Soient deux classes A et B :
- Critère du lien minimum : Dmin (A, B) = min{d(x, y) / x Є A , y Є B}
- Critère du lien maximum : Dmax (A, B) = max{d(x, y) / x Є A , y Є B}
- Critère de Ward :

Le critère de Ward, plus utilisé, montre ses limites dans le cas où les classes sont allongées et donc le critère minimum de vient plus performant.
. La classification hiérarchique descendante
Aussi connue sous le nom d’analyse des associations ou classification par divisions, elle réalise comme son nom l’indique une opération inverse de celle du CAH. Le principe étant de considérer d’abord l’ensemble de données comme un seul cluster et réaliser de façon récursive la segmentation des classes de telle sorte que la dissimilarité soit maximale afin d’obtenir un dendogramme optimal.
Bien que ce type de classification fournisse des résultats cohérents, elle est cependant moins utilisée que la précédente du fait de son temps de calcul très lourd. En effet, si on dispose de N données, il faudrait à cette méthode 2N-1 -1 bipartitions pour n’en choisir qu’une seule (celle qui répond la mieux au critère de scission).
c. L’approche SOM (Self-Organised Map)
Plus connue sous le nom de carte auto-organisatrice (ou carte auto-adaptative) de Kohonen (du nom de son inventeur Teuvo Kohonen), cette technique de classification est en fait une version non supervisée des réseaux de neurones. Elle cartographie les classes de données d'entrée en réalisant une projection, depuis leur espace multidimensionnel d'origine, dans l'espace interne de sa mémoire qui est bidimensionnelle. L'algorithme construit un ordonnancement topologique des relations implicites qu'il découvre entre les classes de données. Sa représentation interne facilite l'analyse des relations entre classes, par la réduction dimensionnelle qu'elle leur applique, et minimise les effets de mauvaise classification. La structure bidimensionnelle de l'espace de représentation fournit une interface de visualisation conviviale où la similarité entre les classes de données est encodée dans la proximité entre les amas d'unités distribuées sur la carte : des formes reliées dans l'espace des données sont situées proches les unes des autres dans l'espace de la carte. Les principaux paramètres de ce modèle sont: le nombre de neurones, le maillage des unités de la carte, la topologie de la carte, tore ou plane le taux d'apprentissage, le voisinage, et les fonctions qui déterminent sa décroissance dans l'espace et dans le temps, le rayon de propagation, le nombre d'itérations, le nombre de phases d'apprentissage.
L’algorithme SOM peut être défini comme suit :

IV. NOTIONS GÉNÉRALES SUR LES APPROCHES PROBABILISTES
Dans les approches probabilistes, les données sont considérées comme un échantillon extrait indépendamment d'un modèle de mélanges de plusieurs distributions de probabilités. La région autour de la moyenne de chaque distribution constitue un cluster naturel. Chaque observation contient en plus de ses attributs l’étiquette du cluster. Différentes méthodes ont été proposées afin de découvrir le meilleur optimum.
La classification probabiliste a plusieurs caractéristiques importantes :
- Elle peut être modifiée dans le but de raccorder les structures complexes ;
- Le modèle de mélange intermédiaire peut être utilisé pour affecter des cas à n’importe quelle étape du processus itératif ;
- La classification probabiliste a pour résultats un système de classes facilement interprétables.
V. APPROCHE PROBABILISTE PROPOSÉE POUR DES DONNÉES BINAIRES
L’algorithme BeSOM utilisé dans ce travail est un algorithme de cartes topographiques dédié aux données catégorielles codées en binaire de façon à ce que chaque cellule de la carte BeSOM soit associée à une fonction de Bernoulli. Les cartes BeSOM sont de la famille des cartes topographiques probabilistes et sont entre autre des modèles de mélange. Le problème revient donc à estimer les paramètres de ces modèles.
L’algorithme BeSOM est en réalité une application directe de l’algorithme E-M (Estimation-Maximisation) [5]:

Trois variantes de BeSOM sont proposées:
- - La première est développée sous l’hypothèse que le paramètre de probabilité dépend uniquement de la cellule ;
- - Dans la deuxième, le paramètre dépend de la cellule et d’une variable ;
- - Dans la troisième, le paramètre dépend uniquement de la carte.
Notre étude se base essentiellement sur la première variante.
1. Validation expérimentale:
Pour valider l’approche proposée on a utilisé deux jeux de données extraits du répositoire UCI [7]. Le premier, concerne une base de données composée de chiffres manuscrits ("0"-"9") extraits à partir d’une collection de cartes des services hollandais. On a 200 exemples pour chaque caractère, ainsi on a au total 2000 exemples. Chaque exemple est une imagette binaire (pixel “noir“ ou ”blanc”) de dimension 15 x 16. L’ensemble de données forme une matrice binaire de dimension 2000 x 240. Chaque variable qualitative est un pixel à deux valeurs possibles "On=1" and "Off=0".
Le deuxième jeu de données utilisé, Zoo data, contient l’information sur 101 animaux décrits par 16 variables qualitatives dont 15 variables sont binaires et une est catégorielle avec 6 modalités. Chaque animal est étiqueté de 1 à 7 conformément à sa classe (son espèce).
On a réalisée plusieurs tests sur ces 2 bases de données et les premiers résultats obtenus sont encourageants.
VI. CONCLUSIONS ET PERSPECTIVES
Le travail effectué dans ce projet se situe dans le domaine du data mining, plus précisément dans le cadre de l’apprentissage non supervisé. Il s’agit d’un problème autour du clustering des données. Le clustering peut être défini comme la segmentation des données en groupes d’objets similaires, d’une telle manière que les objets du même groupe sont similaires entre eux et dissimilaires avec les objets des autres groupes. Ici on s’intéresse plutôt au clustering des données binaires.
Pour réaliser le travail effectué dans le cadre de ce stage on a suivi la démarche suivante :
Afin de comprendre la problématique on a étudié et analysé plusieurs approches qui existent dans le domaine. On a implémenté sous Matlab un algorithme de classification non supervisée pour des données catégorielles et les premiers résultats obtenus sont encourageants. En outre, les outils statistiques utilisés (les cartes SOM et algorithme EM) sont relativement faciles à implémenter informatiquement. Enfin, l’algorithme reste utilisable pour de très grands jeux de données (bien que nous ne l’ayons pas fait ici).
Nous voyons au moins deux directions dans lesquelles ce travail pourrait être poursuivi :
1. Dans un premier temps, on pourrait tester la performance de l’algorithme sur des très grands jeux de données.
2. Par la suite, on pourrait utiliser et tester plusieurs critères de validations ainsi que comparer avec d’autres approches similaires qui existent dans le domaine.
Références bibliographiques
[1] M. Lebbah. Carte topologique pour données qualitatives : application à la reconnaissance automatique de la densité du tra_c routier. Thése de doctorat en Informatique,
Université de Versailles Saint-Quentin en Yvelines, 2003.
[2] Mustapha Lebbah, Aymeric Chazottes, Fouad Badran, and Sylvie Thiria. Mixed
topological map. In ESANN, pages 357_362, 2005.
[3] J.J. Verbeek, N. Vlassis, and B.J.A. Kröse. Self-organizing mixture models.
Neurocomputing, 2005
[4] M. Nadif, J. Priam Cartes auto-organisatrices probabiliste sur données binaires, 2006.
[5] A. Dempster, N. Laird, and D. Rubin. Maximum likelihood from incomplete data via
the EM algorithm. Journal of the Royal Statistical Society, B 39 :1–38, 1977.
[6] C.L. Blake and C.L Merz. UCI repository of machine learning databases.
Technical report. 1998.
[7] N. Rogovschi, Classi cation à base de modèles de mélanges topologiques des
données catégorielles et continues , 2009
données catégorielles et continues , 2009
[8] http://perso.rd.francetelecom.fr
[9] http://www.grappa.univ-lille3.fr
[10] http://docs.happycoders.org
[11] http://liris.cnrs.fr
[12] http://perso.telecom-paristech.fr
[13] http://www.math.u-psud.fr
[14] http://www.jybaudot.fr
[15] http://www.aiaccess.net
...
...
cool
RépondreSupprimerCe commentaire a été supprimé par un administrateur du blog.
RépondreSupprimer